I’m writing these notes to help myself and others review mathematical probability (mostly from an applied perspective). So far, I have covered single-variable probability. I plan to later add sections on joint probability and perhaps a few other topics. My main source is the excellent textbook “Probability, Statistics, and Random Processes” by Hossein Pishro-Nik.
The axioms of probability include: (i) for any event A, P(A) ≥ 0, (ii) the probability of the total sample space S is P(S) = 1, and (iii) if A1,A2,A3,… are disjoint events then P(A1∪A2∪A3…) = P(A1) + P(A2) + P(A3)…
Note that intersection means “and” while union means “or”. Thus P(A∩B) = P(A and B) = P(A,B) while P(A∪B) = P(A or B).
An important tool in probability is the inclusion-exclusion principle. This is given by the following formulas for two events and for n events.
Conditional probability
Consider two events A and B in sample space S. The conditional probability of A given B is defined by the equation below.
Two events are independent if the first equation below holds true. Three events are independent if the second, third, fourth, and fifth equations below all hold true. This logic can be combinatorically extended to n independent events as well.
The law of total probability is an important tool for working with conditional probability. If B1,B2,B3,… represents a partition of the sample space S (the sample space can be “split” or partitioned into n “regions” or disjoint sets Bi), then the law of total probability is given as follows for any event A.
Bayes theorem represents an extremely important and widely consequential tool for conditional probability. Learning the intuition behind Bayes theorem can be highly valuable. The equation for Bayes theorem with two events A and B where P(A) ≠ 0 is given by the first equation below. The equation for Bayes theorem with n events B1, B2, B3… which partition the sample space S while P(A) ≠ 0 is given by the second equation below.
Two events are conditionally independent if they satisfy the following formula.
Random variables
A random variable X is a function mapping the sample space to the real numbers. That is, X is a real-valued function that assigns a value to each possible outcome of a random experiment.
The range of X is the set of possible values for X. As an example, flip a coin 5 times and define X as the number of heads that occur. The range of X is the set RX = {0,1,2,3,4,5}.
Discrete random variables are those which have countable ranges. Examples of countable ranges include finite sets as well as countably infinite sets like ℤ, ℚ, and ℕ.
Continuous random variables are those which have uncountable ranges. Any non-empty subset of ℝ is uncountable (as is the entirety of ℝ).
Probability mass functions
Probability mass functions (PMFs) assign probabilities to the possible values of a discrete random variable. If X is a discrete random variable with a finite or countably infinite range RX = {x1,x2,x3,…,xn}, then P(xk) = P(X = xk) for k = 1,2,3,…,n is the probability mass function of X.
As an example, the PMF for tossing a coin twice and setting X as the number of heads observed is as follows.
As it is a probability measure by definition, the PMF has the properties of a probability measure.
In addition, for any set A which is a subset of RX, the probability that X ∈ A is given as the sum of the probabilities of X for each element of A.
Independent random variables
Consider two discrete random variables X and Y. If the following equation holds true, then X and Y are independent.
X and Y are furthermore independent if knowing the probability of one of them does not alter the probabilities of the other. Note the vertical line “|” denotes “given”, so P(X =x|Y=y) is probability that X=x given that Y=y.
Special discrete distributions
Bernoulli distribution: a random variable X is a Bernoulli random variable with parameter p if its PMF is given by the first equation below. Bernoulli random variables indicate when a certain event A occurs, so they take on a value of 1 if A happens and 0 otherwise. This is described in the second equation below. Here, 0 < p < 1.
Geometric distribution: a random variable X is a geometric random variable with parameter p if its PMF is given by the equation below. The random experiment for this distribution consists of performing repeated independent “Bernoulli” trials until a given outcome (e.g. heads for a coin toss) occurs. The range of X is 1,2,3,… and describes the number of trials before the specified outcome. Here, 0 < p < 1. PX(k) tends to decline as k grows larger since it is more and more likely the specified outcome will have occurred with more trials.
Binomial distribution: a random variable X is a binomial random variable with parameters n and p if its PMF is given by the first equation below. The random experiment for this distribution consists of repeatedly (n times) performing some process which has a probability P(H) = p of yielding an outcome H, then defining X as the total number of times H is observed. Here, 0 < p < 1. Note that the binomial coefficient “n choose k” is given by the second equation below.
Poisson distribution: a random variable X is a Poisson random variable with parameter λ if its range is RX = {0,1,2,3,…} and its PMF is given by the equation below. Poisson distributions are used to describe the count of random occurrences that happen within a certain interval of time or space. For a Poisson distribution, one asks the probability that k events occur will occur within a specified interval wherein an average of λ events are known to happen.
Cumulative distribution functions
The cumulative distribution function (CDF) for a random variable X is defined by the equation below. Note that the CDF is a function over the entire real line, so it must be able to produce an output for any real input value x. An advantage of CDFs is that they can be defined for any type of random variable (discrete, continuous, or mixed).
One can also use CDFs as follows to find the probability that X produces an outcome between two values a and b for which a ≤ b. Note that it is important to pay attention to when the “<” and “≤” symbols can be used.
Expectation
The expectation value E of a discrete random variable X is its average or mean, also described as a weighted average of the values in its range. The expectation value formula is given by the first equation below, along with various equivalent notational options. Here, the range RX of the random variable X can be finite or countably infinite. An important property of expectation is that it is linear. The linearity of expectation is described by the second equation below.
Functions of random variables
If X is a random variable and there is a function Y = g(X), then Y is also a random variable. The range of Y is RY = {g(x) | x ∈ RX} and the PMF of Y is PY(g(X) = y). A convenient way to find the expected value of E[Y] is given by the law of the unconscious statistician (LOTUS), which is described in the equation below. One can also find the PMF of Y and then use the expectation value formula, but this is usually more difficult than using LOTUS.
Variance
The variance of a random variable with mean µX is a measure of the amount of spread of its distribution. It can be found using either of the following first two equations. Some useful properties of variance are given by the second two equations.
Since variance of X has different units than X itself (variance units are the square of the units of X), standard deviation is often used as an alternative measure of distributional spread. Standard deviation is simply the square root of the variance.
Continuous random variables and probability density functions
A random variable X with a CDF of FX(x) is continuous if FX(x) is a continuous function for all x ∈ ℝ.
CDFs work properly for continuous random variables. However, PMFs are invalid for continuous random variables because P(X = x) = 0 for x ∈ ℝ when each P(X = x) corresponds to an infinitesimal slice of the probability. A different tool is needed. Specifically, the probability density function or PDF is utilized. The PDF fX(x) for a random variable X with a continuous CDF FX(x) for all x ∈ ℝ is defined by the first equation below. PDF properties are given by the rest of the equations below.
Expected value and variance for continuous random variables
The expected value and LOTUS for continuous random variables are analogous to those in the discrete case, but with integrals instead of summations. For a continuous random variable X, the expectation value E[X] is given by the first equation below and the LOTUS is given by the second equation below.
Likewise, the variance for a continuous random variable X takes on the following equivalent forms given by the first two equations below. A useful property of continuous variance is given by the third equation below.
Finding PDFs of functions of continuous random variables
The most straightforward way to find the PDF of a continuous random variable is to start with the CDF and take its derivative (assuming the CDF is continuous).
Another way to find the PDF of a function of a continuous random variable Y = g(X) is to use the method of transformations. The simplest form of this approach requires g to be strictly increasing or strictly decreasing (a monotonic function). However, one can generalize the method of transformations by partitioning the domain RX into n intervals (where n is finite) which each are monotonic and differentiable, even if the function is not monotonic as a whole. This approach for finding the PDF is then given by the following equation.
Special continuous distributions
Uniform distribution: a continuous random variable X has a uniform distribution over the interval [a,b] if its PDF is given as follows.
Exponential distribution: a continuous random variable X has an exponential distribution with parameter λ > 0 if its PDF is given as follows.
Standard normal (standard Gaussian) distribution: a continuous random variable Z has a standard normal distribution if its PDF is given as follows (for all z ∈ ℝ). It should be noted that the standard normal distribution can be scaled and shifted to obtain other normal distributions as will be described after this discussion on the standard normal distribution.
The standard normal distribution has E[Z] = 0 and Var(Z) = 1. The CDF Φ(x) of the standard normal distribution is given by the following equation.
Normal (Gaussian) distributions and normal random variables: if Z is a standard normal random variable and X = σZ + µ, then X is a normal random variable with mean µ and variance σ2. That is, X ~ N(µ,σ2). For any normal variable X with mean µ and variance σ2, the PDF is given by the first equation below and the CDF is given by the second equation below. Additionally, the probability P(a < X ≤ b) is given by the third equation below.
An important property of the normal distribution is that a linear transformation of a normal random variable is itself a normal random variable. This is described by the following theorem.
Gamma function and the Gamma distribution: the gamma distribution makes use of the gamma function, which is defined for natural numbers n = {1,2,3,…} by the first equation below and more generally for positive real numbers by the second equation below.
Some properties of the gamma function for any positive real number α > 0 are given by the five equations below.
Now that the definition and properties of the gamma function have been laid out, one can move on to the gamma distribution itself. A continuous random variable X has a gamma distribution over the with parameters α > 0 and λ > 0 if its PDF is given as follows.
Mixed random variables
When a random variable contains both a continuous part and a discrete part, it is called a mixed random variable. Generally speaking, the CDF of a mixed random variable Y can be written as the sum of a continuous function C(y) and a “staircase” function D(y) as described by the equation below. The plot of FY(y) versus y can have continuous curves, discontinuities between the curves and the discrete parts. The discontinuities sometimes take the form of “jumps”.
To obtain the PDF of a mixed random variable Y, one can integrate the continuous part and turn the discrete part into a sum as described by the following equation. Here, {y1,y2,y3,…} are a set of jump points of D(y). That is, they are the points for which P(Y = yk) > 0. With these mechanics, the PDF over negative infinity to infinity as well as over all jump points yk integrates and sums to 1, ensuring that the axioms of probability are satisfied.
By modifying the equation above, one can obtain the expectation value of Y as shown in the following formula.
Dirac delta function and generalized PDFs
The Dirac delta function is not technically a function but a “generalized function” since it outputs an infinite value for x = 0. It is very useful since it can be used to define a PDF for discrete and mixed random variables. The Dirac Delta function δ(x) and its properties are given by the following equations. Note that u(x) is called the unit step function.
By using the Dirac delta function, one can define a generalized PDF for a discrete random variable as follow. For the random variable X here, the range RX = {x1,x2,x3,…} and the PMF is PX(xk).
More broadly, the generalized PDF for a mixed random variable X is given by the first equation below. The second equation below describes how this generalized PDF satisfies the axioms of probability since its integral from negative infinity to infinity is 1.
Overview of the Schrödinger equation and wave functions
Quantum mechanical systems are described in terms of wave functions Ψ(x,y,z,t). Unlike classical functions of motion, wave functions determine the probability that a given particle may occur in some region. The way that this is achieved involves integration and will be discussed later in these notes.
To find a wave function, one must solve the Schrödinger equation for the system in question. There are time-dependent and time-independent versions of the Schrödinger equation. The time-dependent version is given in 1D and 3D by the first pair of equations below and the time-independent version is given in 1D and 3D by the second pair of equations below. Here, ћ is h/2π (and h is Planck’s constant), V is the particle’s potential energy, E is the particle’s total energy, Ψ is a time dependent wave function, ψ is a time-independent wave function, and m is the mass of the particle. After this point, these notes will focus on 1D cases unless otherwise specified (it will often be relatively straightforward to extrapolate to the 3D case).
For a wave function to make physical sense, it needs to satisfy the constraint that its integral from –∞ to ∞ must equal 1. This reflects the probabilistic nature of quantum mechanics; the probability that a particle may be found anywhere in space must be 1. For this reason, one must usually find a (possibly complex) normalization constant A after finding the wave function solution to the Schrödinger equation. This is accomplished by solving the following integral for A. Here, Ψ* is the complex conjugate of the wave function without the normalization constant and Ψ is the wave function without the normalization constant.
To obtain solutions to the time-dependent Schrödinger equation, one must first solve the time-independent Schrödinger equation to get ψ(x). The general solution for the time-dependent Schrödinger equation is any linear combination of the product of ψ(x) with an exponential term (see below). The coefficients cn can be real or complex.
Physically, |cn|2 represents the probability that a measurement of the system’s energy would return a value of En. As such, an infinite sum of all the |cn|2 values is equal to 1. In addition, note that each Ψn(x,t) = ψn(x)e–iEnt/ℏ is known as a stationary state. The reason these solutions are called stationary states is because the expectation values of measurable quantities are independent of time when the system is in a stationary state (as a result of the time-dependent term canceling out).
Using wave functions
Once a wave function is known, it can be used to learn about the given quantum mechanical system. Though wave functions specify the state of a quantum mechanical system, this state usually cannot undergo measurement without altering the system, so the wave function must be interpreted probabilistically. The way the probabilistic interpretation is achieved will be explained over the course of this section.
Before going further, it will be useful to understand some methods from probability. First, the expectation value is the average of all the possible outcomes of a measurement as weighted by their likelihood (it is not the most likely outcome as the name might suggest). Next, the standard deviation σ describes the spread of a distribution about an average value. Note that the square of the standard deviation is called the variance.
Equations for the expectation value and standard deviation are given as follows. The first equation computes the expectation value for a discrete variable j. Here, P(j) is the probability of measurement f(j) for a given j. The second equation is a convenient way to compute the standard deviation σ associated with the expectation value for j. The third equation computes the expectation value for a continuous function f(x). Here, ρ(x) is the probability density of x. When ρ(x) is integrated over an interval a to b, it gives the probability that measurement x will be found over that interval. The fourth equation the same as the second equation, but finds the standard deviation σ for the continuous variable x.
In quantum mechanics, operators are employed in place of measurable quantities such as position, momentum, and energy. These operators play a special role in the probabilistic interpretation of wave functions since they help one to compute an expectation value for the corresponding measurable quantity.
To compute the expectation value for a measurable quantity Q in quantum mechanics, the following equation is used. Here, Ψ is the time-dependent wave function, Ψ* is the complex conjugate of the time-dependent wave function, and Q̂ is the operator corresponding to Q.
Any quantum operator which corresponds to a classical dynamical variable can be expressed in terms of the momentum operator –iℏ(∂/∂x). By rewriting a given classical expression in terms of momentum p and then replacing every p within the expression by –iℏ(∂/∂x), the corresponding quantum operator is obtained. Below, a table of common quantum mechanical operators in 1D and 3D is given.
Heisenberg uncertainty principle
The Heisenberg uncertainty principle explains why quantum mechanics requires a probabilistic interpretation. According to the Heisenberg uncertainty principle, the more precisely the position of a particle is determined via some measurement, the less precisely its momentum can be known (and vice versa). The Heisenberg uncertainty principle is quantified by the following equation.
The reason for the Heisenberg uncertainty principle comes from the wave nature of matter (and not from the observer effect). For a sinusoidal wave, the wave itself is not really located at any particular site, it is instead spread out across the cycles of the sinusoid. For a pulse wave, the wave can be localized to the site of the pulse, but it does not really have a wavelength. There are also intermediate cases where the wavelength is somewhat poorly defined and the location is somewhat well-defined or vice-versa. Since the wavelength of a particle is related to the momentum by the de Broglie formula p = h/λ = 2πℏ/λ, this means that the interplay between the wavelength and the position applies to momentum and position as well. The Heisenberg uncertainty principle quantifies this interplay.
Some simple quantum mechanical systems
Infinite square well
The infinite square well is a system for which a particle’s V(x) = 0 when 0 ≤ x ≤ a and its V(x) = ∞ otherwise. Because the potential energy is infinite outside of the well, the probability of finding the particle there is zero. Inside the well, the time-independent Schrödinger equation is given as follows. This equation is the same as the classical simple harmonic oscillator.
For the infinite square well, certain boundary conditions apply. In order for the wave function to be continuous, the wave function must equal zero once it reaches the walls, so ψ(0) = ψ(a) = 0. The general solution to the infinite square well differential equation is given as the first equation below. The boundary condition ψ(0) = 0 is employed in the second equation below. Since the coefficient B = 0, there are only sine solutions to the equation. Furthermore, if ψ(a) = 0, then Asin(ka) = 0. This means that k = nπ/a (where n = 1, 2, 3…) as given by the third equation below. The fourth equation below shows that this set of values for k leads to a set of possible discrete energy levels for the system
To find the constant A, the wave function ψ = Asin(nπx/a) must undergo normalization. As mentioned earlier, normalization is achieved by setting the normalization integral equal to 1 and solving for the constant A. Note that the time-independent Schrödinger equation can be utilized in the normalization integral since the exponential component of the time-dependent Schrödinger equation would cancel anyways.
Using this information, the wave functions for the infinite square well particle system are obtained. The time-independent and time-dependent wave functions are both displayed below at left and right respectively.
This infinite set of wave functions has some important properties. They possess discrete energies that increase by a factor of n2 with each level (and n = 1 is the ground state). The wave functions are also orthonormal. This property is described by the following equation. Here, δmn is the Kronecker delta and is defined below.
Another important property of these wave functions is completeness. This means that any function can be expressed as a linear combination of the time-independent wave functions ψn. The reason for this remarkable property is that the general solution (see below) is equivalent to a Fourier series.
The first equation below can be employed to compute the nth coefficient cn. Here, f(x) = Ψ(x,0) which is an initial wave function. Note that the initial wave function can be any function Ψ(x,0) and the result will generate coefficients for that starting point. This first equation is derived using the orthonormality of the solution set. Note that the formula applies to most quantum mechanical systems since the properties of orthonormality and completeness hold for most quantum mechanical systems (though there are some exceptions). The second equation below computes the cn coefficients specifically for the infinite square well system.
Quantum harmonic oscillator
For the quantum harmonic oscillator, the potential energy in the Schrödinger equation is given by V(x) = 0.5kx2 = 0.5mω2x2. This means that the following time-independent Schrödinger equation needs to be solved.
There are two main methods for solving this differential equation. These include a ladder operator approach and a power series approach. Both of these methods are quite complicated and will not be covered here. The solutions for n = 0, 1, 2, 3, 4, 5 are given below. Here, Hn(y) is the nth Hermite polynomial. The first five Hermite polynomials and the corresponding energies for the system are given in the table. Note that the discrete energy levels for the quantum harmonic oscillator follow the form (n + 0.5)ћω.
As with any quantum mechanical system, the quantum harmonic oscillator is further described by the general time-dependent solution. To identify the coefficients cn for this general solution, Fourier’s trick is employed (see previous section) where f(x) is once again any initial wave function Ψ(x,0).
Quantum free particle
Though the classical free particle is a simple problem, there are some nuances which arise in the case of the quantum mechanical free particle which greatly complicate the system.
To start, the Schrödinger equation for the quantum free particle is given in the first equation below. Here, k = (2mE)0.5/ћ. Note that V(x) = 0 since there is no external potential acting on the particle. The second equation below is a general time-independent solution to the system in exponential form. The third equation below is the time-dependent solution to the system where the terms are multiplied by e–iEt/ћ. Realize that this general solution can be written as a single term by redefining k as ±(2mE)0.5/ћ. When k > 0, the solution is a wave propagating to the right. When k < 0, the solution is a wave propagating to the left.
The speed of these propagating waves can be found by dividing the coefficient of t (which is ћk2/2m) by the coefficient of x (which is k). Since this is speed, the direction of the wave does not matter, so one can take the absolute value of k. By contrast, the speed of a classical particle is found by solving E = 0.5mv2, which gives a puzzling result that is twice as fast as the quantum particle.
Another challenge associated with the quantum free particle is that its wave function is non-normalizable (as shown below). Because of this, one can conclude that free particles cannot exist in stationary states. Equivalently, free particles never exhibit definite energies.
To resolve these issues with the quantum free particle, it has been found that the wave function of a quantum free particle actually carries a range of energies and speeds known as a wave packet. The solution for this wave packet involves the integral given by the first equation below and a function ϕ(k) given by the second equation below. This second equation allows one to determine ϕ(k) to fit a desired initial wave function Ψ(x,0). It was obtained using a mathematical tool called Plancherel’s theorem.
The above solution to the quantum free particle is now normalizable. Furthermore, the issue with the speed of the quantum free particle having a value twice as large as the speed of the classical free particle is fixed by considering a phenomenon known as group velocity. The waveform of the particle is an oscillating sinusoid (see image). This waveform includes an envelope, which represents the overall shape of the oscillations rather than the individual ripples. The group velocity vg is the speed of this envelope while the phase velocity vp is the speed of the ripples. It can be shown using the definitions of phase velocity and group velocity (see below) that the group velocity is twice the phase velocity, resolving the problem with the particle speed. The group velocity of the envelope is thus what actually corresponds to the speed of the particle.
Interlude on bound states and scattering states
To review, the solutions to the Schrödinger equation for the infinite square well and quantum harmonic oscillator were normalizable and labeled by a discrete index n while the solution to the Schrödinger equation for the free particle was not normalizable and was labeled by a continuous variable k.
The solutions which are normalizable and labeled by a discrete index are known as bound states. The solutions which are not normalizable and are labeled by a continuous variable are known scattering states.
Bound states and scattering states are related to certain classical mechanical phenomena. Bound states correspond to a classical particle in a potential well where the energy is not large enough for the particle to escape the well. Scattering states correspond to a particle which might be influenced by a potential but has a large enough energy to pass through the potential without getting trapped.
In quantum mechanics, bound states occur when E < V(∞) and E < V(–∞) since the phenomenon of quantum tunneling allows quantum particles to leak through any finite potential barrier. Scattering states occur when E > V(∞) or E > V(–∞). Since most potentials go to zero at infinity or negative infinity, this simplifies to bound states happening when E < 0 and scattering states happening when E > 0.
The infinite square well and the quantum harmonic oscillator represent bound states since V(x) goes to ∞ when x → ±∞. By contrast, the quantum free particle represents a scattering state since V(x) = 0 everywhere. However, there are also potentials which can result in both bound and scattering states. These kinds of potentials will be explored in the following sections.
Delta-function well
Recall that the Dirac delta function δ(x) is an infinitely high and infinitely narrow spike at the origin with an area equal to 1 (the area is obtained by integrating). The spike appears at the point a along the x axis when δ(x – a) is used. One important property of the Dirac delta function is that f(x)δ(x – a) = f(a)δ(x – a). By integrating both sides of the equation of this property, one can obtain the following useful expression. Note that a ± ϵ is used as the bounds since any positive value ϵ will then allow the bounds to encompass the Dirac delta function spike.
The delta-function well is a potential of the form –αδ(x) where α is a positive constant. As a result, the time-independent Schrödinger equation for the delta-function well system is given as follows. This equation has solutions that yield bound states when E < 0 and scattering states when E > 0.
For the bound states where E < 0, the general solutions are given by equations below. The substitution κ is defined by the first equation below, the second equation below is the general solution for x < 0, and the third equation below is the general solution for x > 0. (Since E is assumed to have a negative value, κ is real and positive). Note that V(x) = 0 for x < 0 and x > 0. In the solution for x < 0, the Ae–κx term explodes as x → –∞, so A must equal zero. In the solution for x > 0, the Feκx term explodes as x → ∞, so F must equal zero.
To combine these equations, one must use appropriate boundary conditions at x = 0. For any quantum system, ψ is continuous and dψ/dt is continuous except at points where the potential is infinite. The requirement for ψ to exhibit continuity means that F = B at x = 0. As a result, the solution for the bound states can be concisely stated as follows. In addition, a plot of the delta-function well’s bound state time-independent wave function is given below.
The presence of the delta function influences the energy E. To find the energy, one can integrate the time-independent Schrödinger equation for the delta-function well system. By making the bounds of integration ±ϵ and then taking the limit as ϵ approaches zero, the integral works only on the negative spike of the delta function at x = 0. The result for the energy is at the end of the following set of equations.
As seen above, the delta-function well only exhibits a single bound state energy E. By normalizing the wave function ψ(x) = Be–κ|x|, the constant B is found (as seen in the first equation below). The second equation below describes the single bound state wave function and reiterates the single bound state energy associated with this wave function.
For the scattering states where E > 0, the general solutions are given by equations below. The substitution k is defined by the first equation below, the second equation below is the general solution for x < 0, and the third equation below is the general solution for x > 0. (Since E is assumed to have a positive value, k is real and positive). Note that V(x) = 0 for x < 0 and x > 0. None of the terms explode this time, so none of the terms can be ruled out as equal to zero.
As a consequence of the requirement for ψ(x) to be continuous at x = 0, the following equation involving the constants A, B, F, and G must hold true. This is the first boundary condition.
There is also a second boundary condition which involves dψ/dx. Recall the following step (see first equation below) from the process of integrating the Schrödinger equation. To implement this step, the derivatives of ψ(x) (see second equation below) are found and then the limits of these derivatives from the left and right directions are taken (see third equation below). Since ψ(0) = A + B as seen in the equation above, the second boundary condition can be given as the final equation below.
By rearranging the final equation above and substituting in a parameter β = mα/ћ2k, the following expression is obtained. This expression is a compact way of writing the second boundary condition.
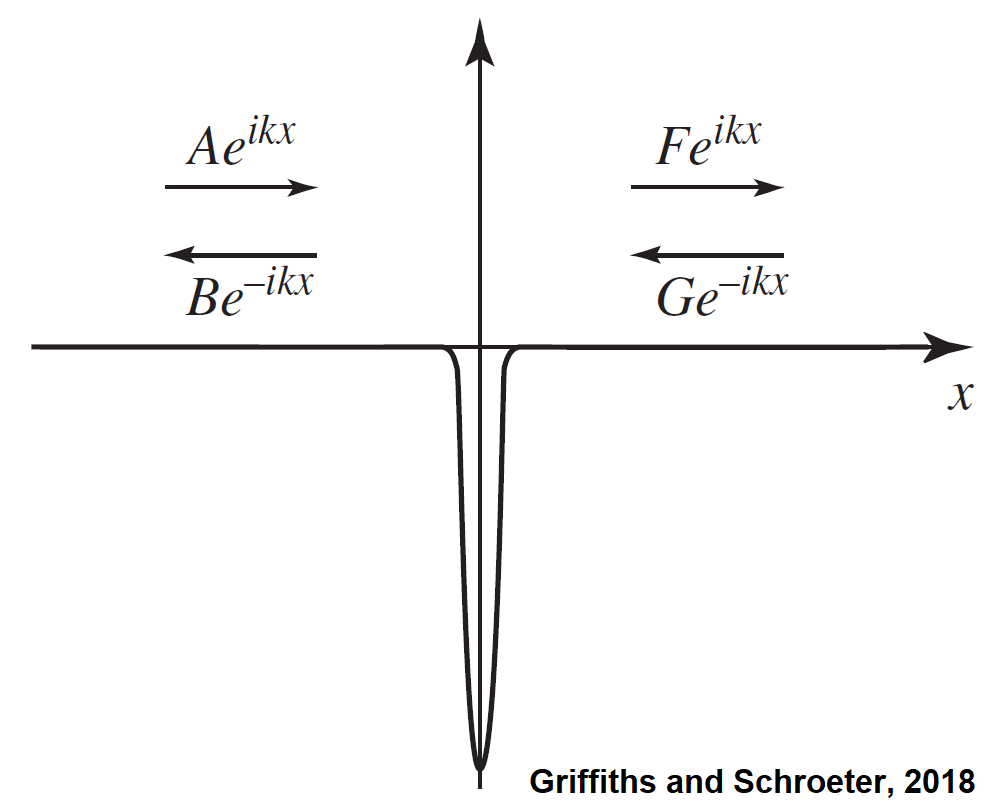
These two boundary conditions provide two equations, but there are four unknowns in these equations (five unknowns if k is included). Despite this, the physical significance of the unknown constants can be helpful. When eikx is multiplied by the factor for time-dependence e–iEt/ћ, it gives rise to a wave propagating to the right. When e–ikx is multiplied by the factor for time-dependence e–iEt/ћ, it gives rise to a wave propagating to the left. As a result, the constants describe the amplitudes of various waves. A is the amplitude of a wave moving to the right on the x < 0 side of the delta-function potential, B is the amplitude of a wave moving to the left on the x < 0 side of the delta-function potential, F is the amplitude of a wave moving to the right on the x > 0 side of the delta-function potential, and G is the amplitude of a wave moving to the left on the x > 0 side of the delta-function potential.
In a typical experiment on this type of system, particles are fired from one side of the delta-function potential, the left or the right. If the particles are coming from the left (moving to the right), the term with G will equal zero. If the particles are coming from the right (moving to the left), the term with A will equal zero. This can be understood intuitively by examining the figure above.
As an example, for the case of particles fired from the left (moving to the right), A is the amplitude of the incident wave, B is the amplitude of the reflected wave, and F is the amplitude of the transmitted wave. The equations of the two boundary conditions are reiterated in the first line below. By solving these equations, the second line of expressions is found. Since the probability of finding a particle at a certain location is |Ψ|2, the relative probability R of an incident particle undergoing reflection and the relative probability T of an incident particle undergoing transmission are given by the third line of expressions below.
Also for the example case of particles fired from the left (moving to the right), by substituting back from β = mα/ћ2k and k = (2mE)0.5/ћ to get the expressions in terms of energy, the following equations are obtained for the reflection and transmission relative probabilities.
By performing the same process, but with A = 0 instead of G = 0, corresponding equations can be found for the case of particles fired from the right (moving towards the left).
It is important to note that, since these scattering wave functions are not normalizable, they do not actually represent possible particle states. To solve this problem, one must construct normalizable linear combinations of the stationary states in a manner similar to that performed with the quantum free particle system. In this way, wave packets will occur and the actual particles will be described by the range of energies of the wave packets. Because the actual normalizable system exhibits a range of energies, the probabilities R and T should be thought of as approximate measures of reflection and transmission for particles with energies in the vicinity of E.
Finite square well
The finite square well is a system for which a particle’s V(x) = –V0 when –a ≤ x ≤ a and its V(x) = 0 otherwise. For this system, the Schrödinger equation is given as follows for the conditions x < –a, –a ≤ x ≤ a, and x > a. Note that the equations for x < –a and x > a are the same since V(x) = 0 in both cases (but the boundary conditions will differ as will be explained soon). As with the Delta-function potential well, the finite square well has both bound states (with E < 0) and scattering states (with E > 0). First, the bound states with E < 0 will be considered. In this case, the Schrödinger equations for the finite square well are as follows.
For the cases of x < –a and x > a where V(x) = 0, the general solutions to the Schrödinger equation are respectively Ae–κx + Beκx and Fe–κx + Geκx where A, B, F, and G are arbitrary constants. In the x < –a case, the Ae–κx term blows up as x → –∞, making this term physically invalid. As a result, the physically admissible solution is ψ(x) = Beκx. In the x > a case, the Geκx term blows up as as x → ∞, making this term physically invalid. As a result, the physically admissible solution is ψ(x) = Fe–κx. For the case of –a ≤ x ≤ a, the general solution to the Schrödinger equation is ψ(x) = Csin(lx) + Dcos(lx). Note that, because E must be greater than the minimum potential energy Vmin = –V0, the value of l ends up real and positive (even though E is also negative). These solutions are summarized by the following equations.
Since the potential V(x) = –V0 is an even function (symmetric about the y axis), one can choose to write the solutions to the wave function as either even or odd. This comes from some properties of the time-independent Schrödinger equation. Next, it is again important to constrain these solutions using the boundary conditions which require the continuity of ψ(x) and dψ/dx at ±a.
For the even solutions, the constant C in ψ(x) = Csin(lx) + Dcos(lx) is zero. Because C = 0, the remaining equation is the even function ψ(x) = Dcos(lx) for –a ≤ x ≤ a. So, the continuity of ψ(x) and dψ/dx at +a necessitates the following two equations to hold true. The third equation comes from dividing the second equation by the first equation to solve for κ.
For the odd solutions, the constant D in ψ(x) = Csin(lx) + Dcos(lx) is zero. Because D = 0, the remaining equation is the odd function ψ(x) = Dsin(lx) for –a ≤ x ≤ a. So, the continuity of ψ(x) and dψ/dx at +a necessitates the following two equations to hold true. The third equation comes from dividing the second equation by the first equation to solve for κ.
As κ and l are both functions of E, the κ = ltan(la) and κ = –lcot(la) equations can be solved for E. To do this, it is convenient to use the notation z = la and z0 = (a/ћ)(2mV0)0.5. Simplifying the κ = ltan(la) and κ = –lcot(la) equations using this notation gives the following results. These equations can be solved numerically for z or graphically for z by looking for points of intersection (after obtaining z, E is easily computed).
Let us consider the tan(z) equation. There are two limiting cases of interest. These include a well which is wide and deep and a well which is shallow and narrow. Though not included in these notes, similar calculations can be performed for the –cot(z) equation.
For a wide and deep well, the value of z0 is large. Intersections between the curves of tan(zn) and ((z0/zn)2 – 1)0.5 occur at nπ/2 for odd n and at nπ for even n. This leads to the following equations which describe values of En. From this outcome, it can be seen that infinite V0 results in the infinite square well case with an infinite number of bound states. However, for any finite square well, there are only a finite number of bound states.
For a shallow and narrow well, the value of z0 is small. As the value of z0 decreases, fewer and fewer bound states exist. Once z0 is smaller than π/2, there is only one bound state (which is an even bound state). Interestingly, no matter how small the well, this one bound state always persists.
The scattering states, which occur when E > 0, will now be considered. In this case, the Schrödinger equations for the finite square well are as follows.
The general solutions to the Schrödinger equation for the finite square well’s scattering states are as follows.
But recall that in a typical scattering experiment, particles are fired from one side of the delta-function potential, the left or the right. Here it will be assumed that the particles are fired from the left side of the well (moving towards the right). Note that similar calculations could be performed for the opposite case. With this assumption, one can realize that the coefficient A represents the incident (from the left) wave’s amplitude, the coefficient B represents the reflected wave’s amplitude, and the coefficient F represents the transmitted (to the right) wave’s amplitude. Finally, the coefficient G = 0 since there is not an incident wave from the right moving towards the left.
There are four boundary conditions, continuity of ψ(x) at ±a and continuity of dψ/dx at ±a. These boundary conditions yield the following equations.
With the above equations, one can eliminate C and D and subsequently solve the system for B and F. This yields the equations below for B and F.
As with the delta-function well, a transmission coefficient T = |F|2/|A|2 can be computed across the finite square well. Recall that T represents the probability of the particle undergoing transmission across the well (in this case when moving from the right side to the left side). The probability of the particle undergoing reflection is R = 1 – T.
Since 1/T equals the equation below, whenever the sine squared term is zero, the probability of transmission T = 1.
Recall that a sine (or sine squared) term is zero when the function inside of it equals nπ such that n is any integer.
Remarkably, the above equation is the same as the one which describes the infinite square well’s energies. But realize that, for the finite square well, this only holds in the case of T = 1.
Reference: Griffiths, D. J., & Schroeter, D. F. (2018). Introduction to Quantum Mechanics (3rd ed.). Cambridge University Press. https://doi.org/DOI: 10.1017/9781316995433
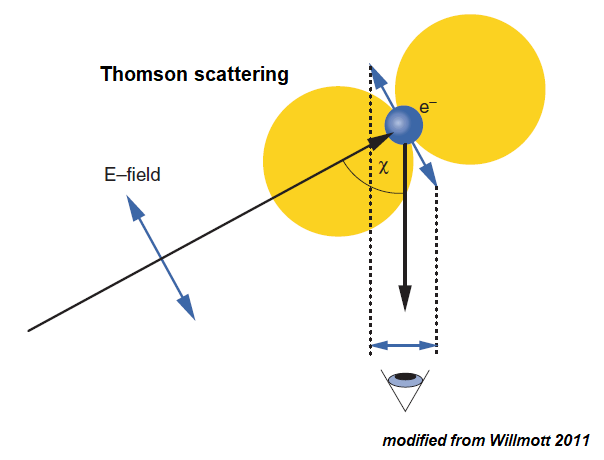
Electrons are the main type of particle that can scatter x-rays. Elastic or Thomson scattering occurs when a non-relativistic electron is accelerated by the electrical component of an incoming electromagnetic field from an x-ray. The accelerated electron then reradiates light at the same frequency. Since the frequency of the input light and output light are the same, this is an elastic process.
The intensity of the re-emitted radiation at an observer’s location depends on the angle Χ between the incident light and the observer. Because of the sinusoidal wave character of light, the scattered intensity at the observer’s location is given by the proportionality equation below.
Light that encounters the electron is scattered if it is incident on the region defined by the electron’s classical radius. This region is called the Thomson scattering length r0. For a free electron, r0 = 2.82×10-5 Å.
Compton scattering occurs when an electron scatters a photon and the scattered photon has a lower energy than the incident photon (an inelastic process). For Compton scattering, a fraction of the incident photon’s energy is transferred to the electron.
The amount of energy lost via Compton scattering where the incident photon has energy E0 = hc/λ0 and the scattered photon has energy E1 = hc/λ1 is described by the following equation. Here, ψ represents the angle between the paths of the incident photon and the scattered photon.
Scattering from atoms
X-rays are scattered throughout the volumes of atomic electron clouds. For x-rays that scattered in the same direction as the incident x-rays, the strength of scattering is proportional to the atom’s Z-number. In the case of an ionic atom, this value is adjusted to equal the atom’s number of electrons. Note that this assumes free electron movement within the cloud.
By contrast, x-rays that are scattered at some angle 2θ relative to the incident x-rays exhibit lower scattering magnitudes. Each of the x-rays scattered at angle 2θ will possess different magnitudes and phases depending on where they were scattered from within the atomic cloud. As a result, the scattering amplitude for the x-rays at angle 2θ will be a vector sum of these waves with distinct magnitudes and phases.
A wavevector k is a vector with magnitude 2π/λ that points in the direction of a wave’s propagation. The difference between the wavevector of the incident wave k0 and the wavevector of the scattered wave k1 is equal to a scattering vector Q (that is, Q = k0 – k1). The magnitude of Q is given by the following equation.
The atomic scattering factor f describes the total scattering amplitude for an atom as a function of sin(θ)/λ. By assuming that the atom is spherically symmetric, f will depend only on the magnitude of Q and not on its orientation relative to the atom. Values for f can be found in the International Tables for Crystallography or computed using nine known coefficients a1,2,3,4, b1,2,3,4, and c (which can also be looked up) and the following expression. The coefficients vary depending on the atom and ionic state. The units of f are the scattering amplitude that would be produced by a single electron.
If the incident x-ray has an energy that is much less than that of an atom’s bound electrons, the response of the electrons will be damped due to their association with the atom. (This no longer assumes free electron movement within the cloud). As a result, f will be decreased by some value fa. The value fa increases when the incoming x-ray’s energy is close to the energy level of the electron and decreases when the incoming x-ray’s energy is far above the energy levels of the electrons.
When the incident x-ray’s energy is close to an electron’s energy level (called an absorption edge), the x-ray is partially absorbed. With this process of partial absorption, some of the radiation is still directly scattered and another part of the radiation is re-emitted after a delay. This re-emitted radiation interferes with the directly scattered radiation. To mathematically describe the effect of the re-emitted radiation’s phase shift and interference, f is adjusted by a second term fb (which is an imaginary value). Far from absorption edges, fb has a much weaker effect (it decays by E-2). The total atomic scattering factor is then given by the following complex-valued equation.
Refraction, reflection, and absorption
A material’s index of refraction can be expressed as a complex quantity nc = nRe + inIm. The real part represents the rate at which the wave propagates through the material and the imaginary part describes the degree of attenuation that the wave experiences as it passes through the material.
The reason that a material can possess a complex refractive index involves the complex plane wave equation. The wavenumber k = 2π/λ0 is the spatial frequency in wavelengths per unit distance and it is a constant within the complex plane wave equation (λ0 is the wave’s vacuum wavelength). The complex wavenumber kc = knc is the wavenumber multiplied by the complex refractive index. As such, the complex refractive index can be related to the complex wavenumber via kc = 2πnc/λ0 where λ0 is the vacuum wavelength of the wave. After inserting 2π(nRe + inIm)/λ0 into the complex plane wave equation, a decaying exponential can be simplified out as a coefficient for the rest of the equation. The decaying exponential represents the attenuation of the wave in the material. Once this simplification is performed, the equation’s complex wavenumber is converted to a real-valued wavenumber.
For x-rays, a material’s complex refractive index for wavelength λ is related to the atomic scattering factors of atoms in the material using the following equation. Ni represents the number of atoms of type j per unit volume and fj(0) is the atomic scattering factor in the forward direction (angle of zero) for atoms of type j. Recall that r0 is the Thomson scattering length.
The refractive index is a function of the wavelength. For most optical situations, as the absorption maximum of a material is approached from lower frequencies, the refractive index increases. But when the radiation’s frequency is high enough that it passes the absorption maximum, the refractive index decreases to a value of less than one.
The refractive index is defined by n = c/v, where v is the wave’s phase velocity. Phase velocity is the rate at which a wave’s phase propagates (i.e. how rapidly one of the wave’s peaks moves through space). Rearranging the equation, v = c/n is obtained. When the refractive index is less than one, the phase velocity is greater than the speed of light. However, this does not violate relativity because the group velocity (not the phase velocity) carries the wave’s energy and information. For comparison, group velocity is the rate at which a change in amplitude of an oscillation propagates.
Anomalous dispersion occurs when the radiation’s frequency is high enough that the refractive index of a material is less than one. As a result, x-rays entering a material from vacuum are refracted away from the normal of the refracting surface. This is in contrast to the typical case where the radiation would be refracted toward the normal of the refracting surface. In addition, the refracted wave is phase shifted by π radians.
The complex refractive index is often expressed using the equation below. Here, δ is called the refractive index decrement and β is called the absorption index. Note that nRe = 1 – δ and nIm = β (as a comparison to the previously used notation). Recall that nIm = β describes the degree of a wave’s attenuation as it moves through a material.
The refractive index decrement can be approximately computed using the average density of electrons ρ, the Thomson scattering length r0, and the wavenumber k = 2π/λ0. Note that this approximation is better for x-rays that are far from an absorption edge.
With most materials, the resulting real part of the index of refraction is only slightly less than one when dealing with x-rays. For example, a typical electron density of one electron per cubic Angstrom yields a δ value of about 5×10-6.
Snell’s law applies to the index of refraction for x-rays and is given as follows.
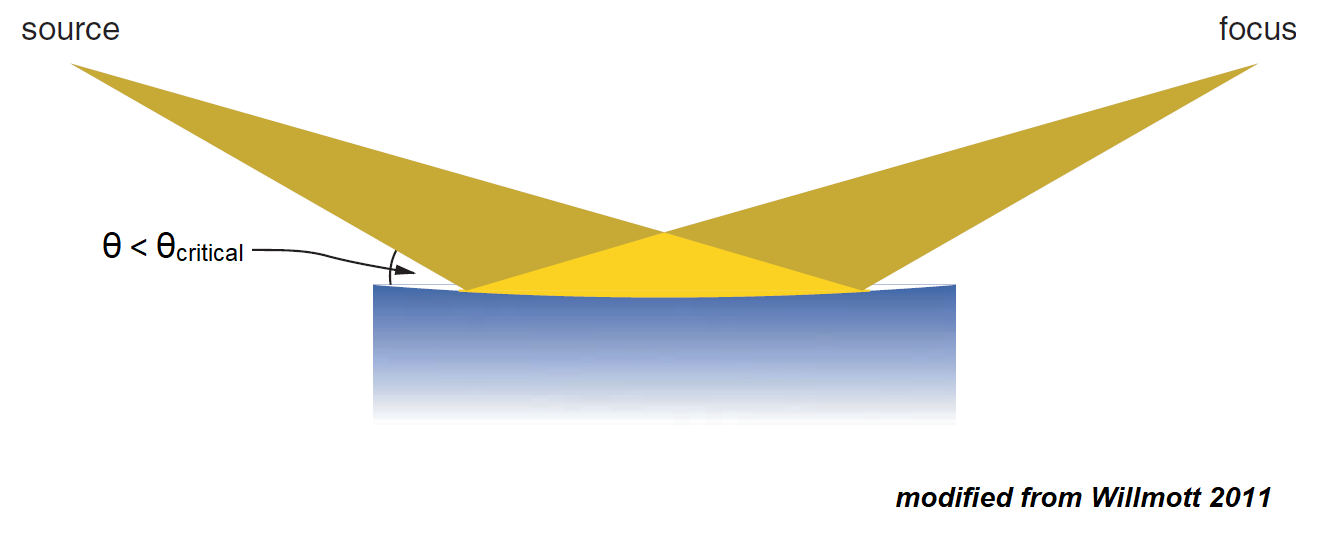
Because the index of refraction for x-rays is slightly less than one, total external reflection can occur when x-rays are incident on a surface at angles less than the critical angle θcritical. This stands in contrast with the total internal reflection that commonly occurs with visible light.
The critical angle can be approximated with a high level of accuracy using the following equation (derived from the Taylor expansion of the cosine function). With typical values of δ on the order of 10-5, θcritical is often equal to just a few milliradians (or a few tenths of a degree). These small angles relative to the surface are called grazing angles.
Because grazing incident angles facilitate x-ray reflection, special curved mirrors can be used to focus x-rays. The curvature of these mirrors must be small enough that the steepest incident angle is less than θcritical. It should be noted that, even when undergoing total external reflection, x-rays do penetrate the reflecting material to a depth of a few nanometers via an evanescent wave.
The absorption index β is related to the value fb using the following equation where r0 is the Thomson scattering length. Recall that fb represents the effects of scattering from absorption and remission of x-rays with energies that are close to the absorption edges of a material.
Using the process explained earlier for computing the decaying exponential exp(-2πnImx/λ0) that represents the attenuation of a wave’s amplitude as it travels through a material, the decay of a wave’s intensity as it travels through a material can also be found. Recall that λ0 is the wavelength in a vacuum. Because intensity is proportional to the square of the amplitude, the equation below describes the exponential decay of a wave’s intensity in a material. (This decaying exponential function is multiplied by the equation of the wave). Here, μ is called the absorption coefficient and is defined as the reciprocal of the thickness of a material required to decrease a wave’s intensity by a factor of 1/e. The absorption coefficient is a rough indication of a material’s electron density and electron binding energy.
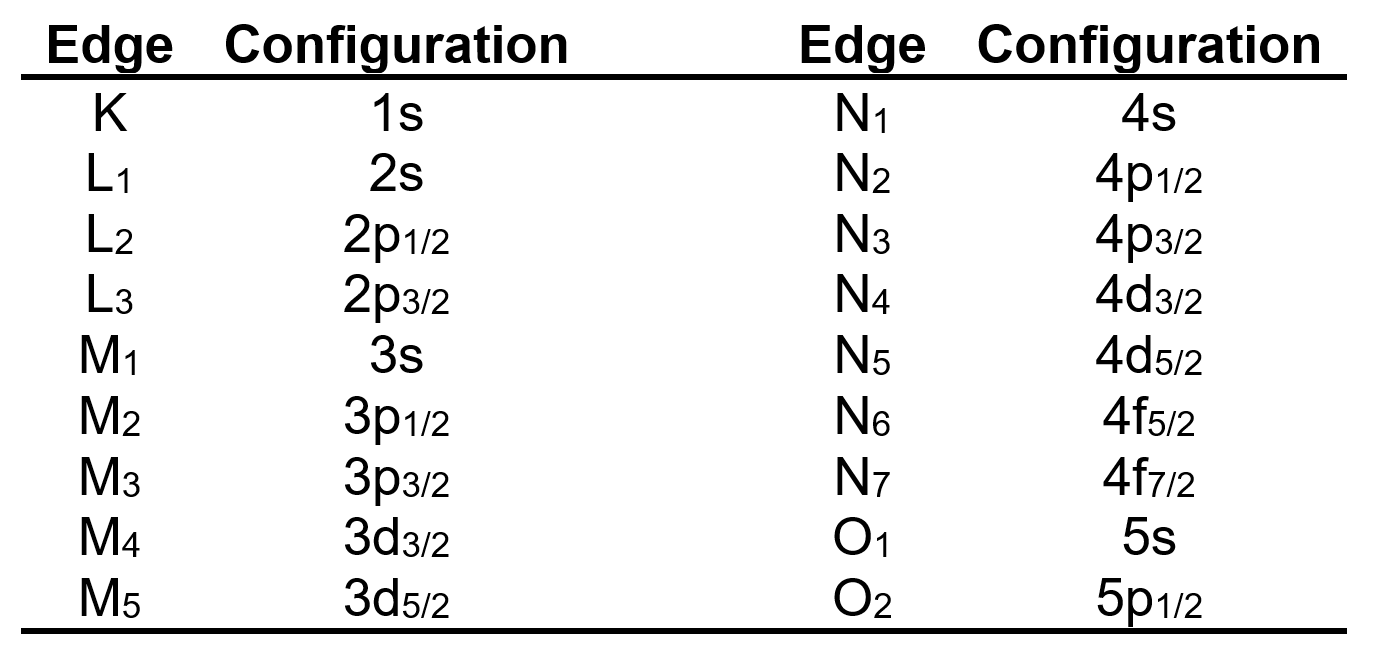
The correspondences between the atomic configurations associated with an x-ray absorption edge and the commonly used name for said absorption edge are given in the following table. The subscripts used with the configurations represent the total angular momenta.
X-ray fluorescence and Auger emission
Materials fluoresce after bombardment with x-rays or high-energy electrons. If electrons are used, the emitted light consists of Bremsstrahlung radiation (which comes from the deacceleration of the electrons) and fluorescence lines. The Bremsstrahlung radiation includes a broad spectrum of wavelengths and has low intensity while the fluorescence lines are sharp peaks and exhibit high intensity. If x-rays are used to bombard a material, there is no Bremsstrahlung radiation, but fluorescence lines occur.
Different materials exhibit different characteristic fluorescence lines. These x-ray fluorescence lines are caused by outer-shell electrons relaxing to fill the holes left after the ejection of photoelectrons. However, not all electronic transitions are allowed, only those which follow the selection rules for electric dipoles. These selection rules are given below. J is the total angular momentum and can be computed from the sum of the Azimuthal quantum number L (which determines the type of atomic orbital) and the spin quantum number S (which determines the direction of an electron’s spin).
The nomenclature for x-ray fluorescence lines is based on the shell to which an electron relaxes. If an excited electron relaxes to the 1s shell state, then the fluorescence line is part of the K series. For an excited electron that relaxes to the 2s or 2p state, the fluorescence line is part of the L series. The M series includes relaxations to 3s, 3p, and 3d. The N series includes relaxations to 5s, 5p, 5d, and 5f. As such, the Azimuthal quantum number determines if the fluorescence line falls into the K, L, M, or N series (there are some series beyond these as well which follow the same pattern). The transition within each series that exhibits the smallest energy difference is labeled with α (i.e. Kα), the transition with the next smallest energy difference is labeled with β, and so on. It should be noted that the fluorescence lines are further split by the effects of electron spin and angular momentum and so are labeled with suffixes of 1, 2, etc.
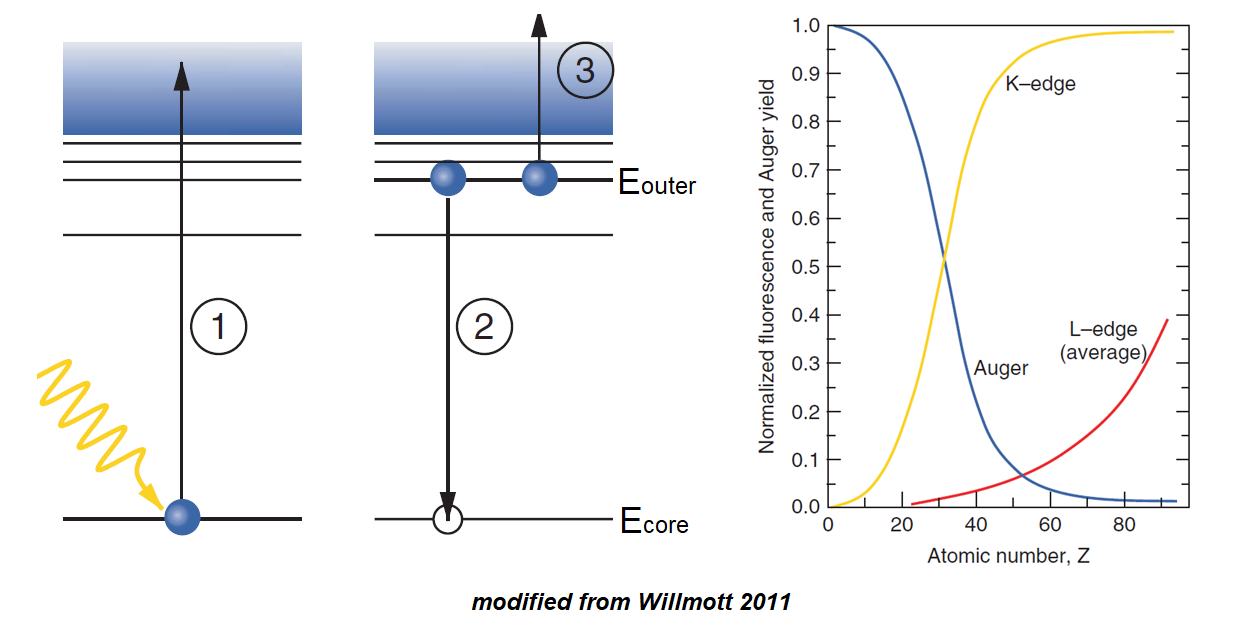
Auger emission is the process where a photoelectron is ejected, an outer shell electron relaxes to fill the hole, and the released energy causes ejection another electron instead of emitting a photon. The energies of emitted Auger electrons are independent of the energies of the incident photons.
The excess energy released by the relaxation of the outer shell electron is equal to |Ecore – Eouter|. In order for the last electron ejection to occur, the electron must have a binding energy that is less than the excess released energy from the relaxation. The kinetic energy of the ejected Auger electron is |Ecore – Eouter – Ebinding|. Note that Ebinding is the binding energy of the Auger electron in the ionized atom (which is different from the binding energy in the neutral form of the atom).
Auger emission and x-ray fluorescence are competitive with each other. Fluorescence is stronger for heavier atoms (higher Z-number) since they exhibit larger energy differences between adjacent shells as well as binding electrons more tightly. For the same reasons, Auger emission is stronger from atoms with lower Z-numbers.
Reference: Willmott, P. (2011). An Introduction to Synchrotron Radiation: Techniques and Applications. Wiley.
Algebraic manipulation of mathematical objects provides a rich array of tools for deriving insights about said objects. Graph theory concerns networks of vertices and edges and finds applications in diverse areas such as computer science, quantitative sociology, electrical engineering, and neurobiology. The use of algebraic methods in graph theory has received surprisingly little attention. While mappings are sometimes studied in graph theory, such transformations are often considered in the abstract, without a method for describing the content of any given mapping. Here, I define an algebraic framework for specifying transformations between graphs. This framework might be extended to further capitalize upon the tools of analysis and abstract algebra, leading to potential new paths of investigation.
Let G and H be simple, labeled graphs. The transformation ϕ(G):𝔾→𝔾 is a mapping which transforms G into H. (Here, 𝔾 represents the set of all simple, labeled graphs). To specify the precise content of this process, I define a general formula for graph mappings. Note that any term may take on either a positive or a negative value. Positive terms indicate the creation of a new vertex or edge within H, while negative terms indicate the removal of an existing vertex or edge from G. In this formula, v∈{V(G),V(H)} and e∈{E(G),E(H)}.
In order for the equation above to be defined, any edge must connect a pair of vertices in H. That is, no edge e can be created without also creating a pair of corresponding vertices that are connected by e. Below, I will provide a specific example of a mapping between graphs to show this formula’s mechanics.
Figure 1 Illustrative example of an algebraic graph mapping ϕ(G)=H and its corresponding labeled graphs.
The algebraic manipulations enabled by this approach remain somewhat limited since every new vertex and edge and every deleted vertex and edge must be explicitly specified. However, as with manipulations of other mathematical objects, taking advantage of patterns can allow abstraction to larger and more complicated systems. For example, sequences and series are often utilized for such purposes in the field of analysis. To move towards analogous investigations on graphs, I will describe a framework for graph labeling which eases the manipulation of complex networks using my algebraic technique.
Let 𝒵 represent a set of “potential vertices” equipped with labels corresponding to the integers. It should be noted that this setup allows for infinite isomorphic graphs with different labelings to be constructed. Each point in 𝒵 is labeled as x∈ℤ. The points x∈𝒵 define the set of possible vertices v∈H which might be created when ϕ operates upon G. In this way, symbolic extrapolations to large networks can be made.
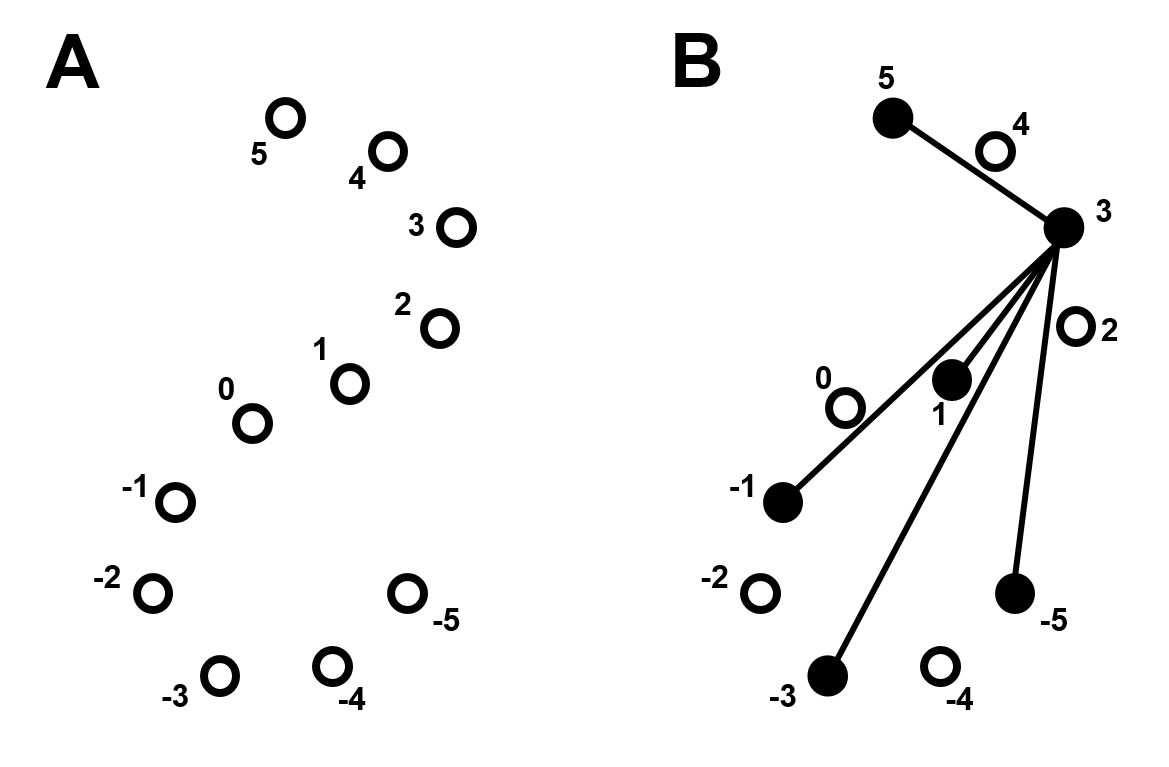
Figure 2 (A) The layout of “potential vertices” described by 𝒵 with bounds x∈[-5,5]. (B) An example of a labeled graph defined on 𝒵 with the same bounds.
Using the labeling scheme 𝒵, functions on ℤ can facilitate the construction of complex networks according to defined rules. Let the variable x take on integer values such that x∈ℤ. To map between graphs on 𝒵, use functions which satisfy F𝒵:ℤ→ℤ to specify the vertices and edges of H. Note that such functions will create infinite graphs unless bounds are defined on x. To facilitate the construction of networks, this scheme will follow three useful rules. (1) If repeated vertices and edges are created, the copies of the repeated vertices and edges will be ignored. (2) If a nonexistent vertex or edge is subtracted, giving a negative vertex or edge, the negative object will be ignored. (3) Any edges or vertices which do not belong to G or H will be ignored.
Figure 3(A) The graph G consists of a single vertex v(0). (B) The function F𝒵 maps G to a graph H using the labeling scheme 𝒵. Edges are created linking v(3) and the rest of the vertices, all negative-labeled vertices edges incident with v(3) are removed, and then all edges linking v(0) and any existing negative-labeled vertices are created. (C) Isomorphism on H to provide a cleaner visualization of the result.
Here, I have developed an algebraic toolset for describing mappings between graphs. This toolset allows the creation of new vertices and edges as well as the removal of existing vertices and edges. To allow rapid generation of networks with many vertices and edges, I have provided a method for consistently labeling graphs that works synergistically with the core algebraic technique. This method may provide the basis for more generalized explorations which utilize such mathematical resources as groups and group-like structures. Because the method lends itself to creating infinite graphs, it may also stimulate investigation from the perspective of analysis using concepts like limits and convergence. The relationships between my algebraic graph mappings and matrix-based representations of graphs may also provide new territory. Applied computational fields may benefit from the mapping technique since it provides an alternative set of resources for investigating and modeling networks. Algebraic graph mappings may provide a nucleation point for a myriad of possible research directions.
Disclaimer: because I come from a biological background and have very limited formal mathematical training, this text may appear quite rough to more mathematically-experienced individuals. However, I feel that the technique has potential to develop further and be applied to problems in science and engineering. I would welcome any constructive critiques so long as they are presented in a respectful manner.





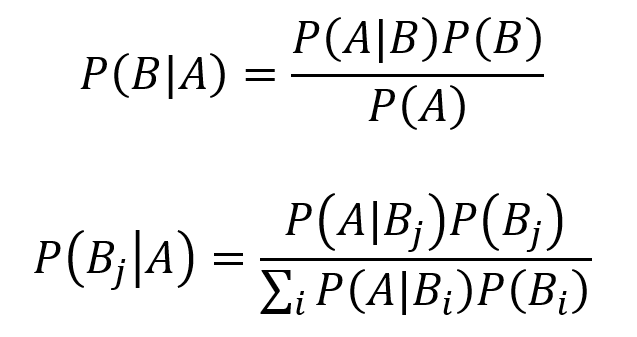


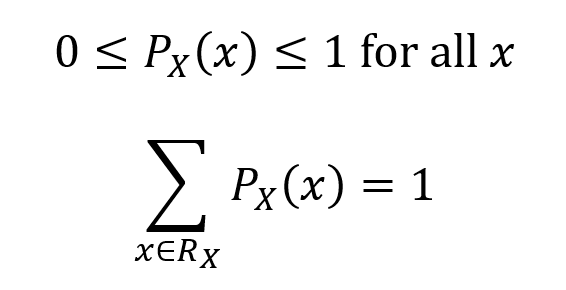

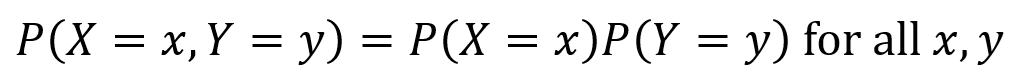
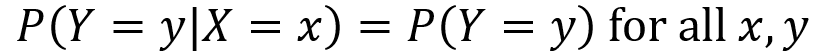

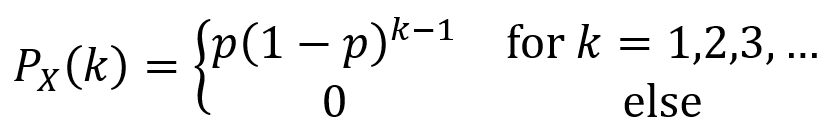



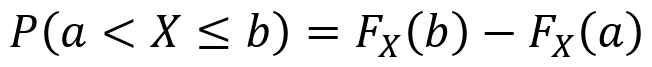
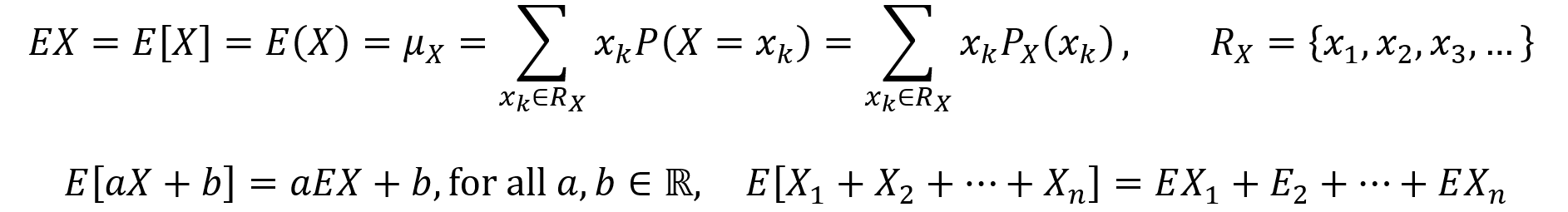




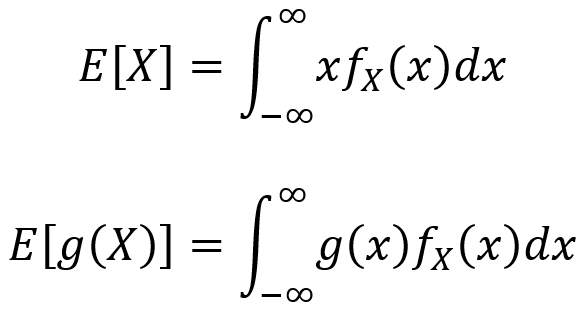





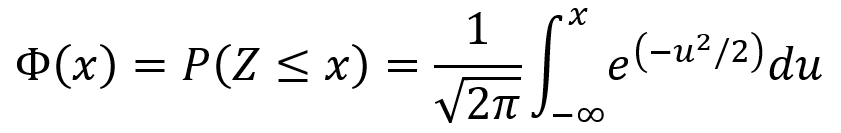

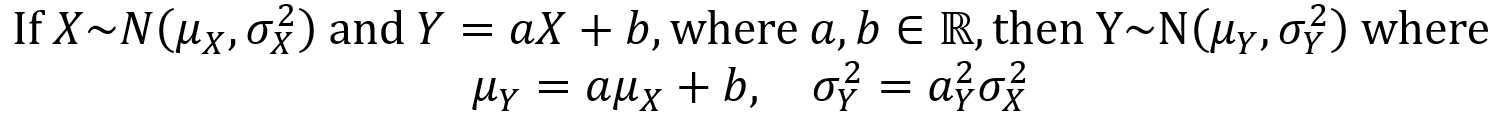


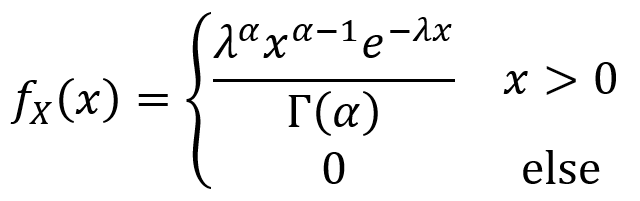

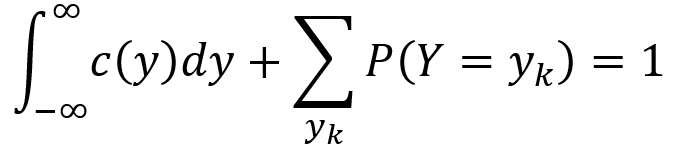

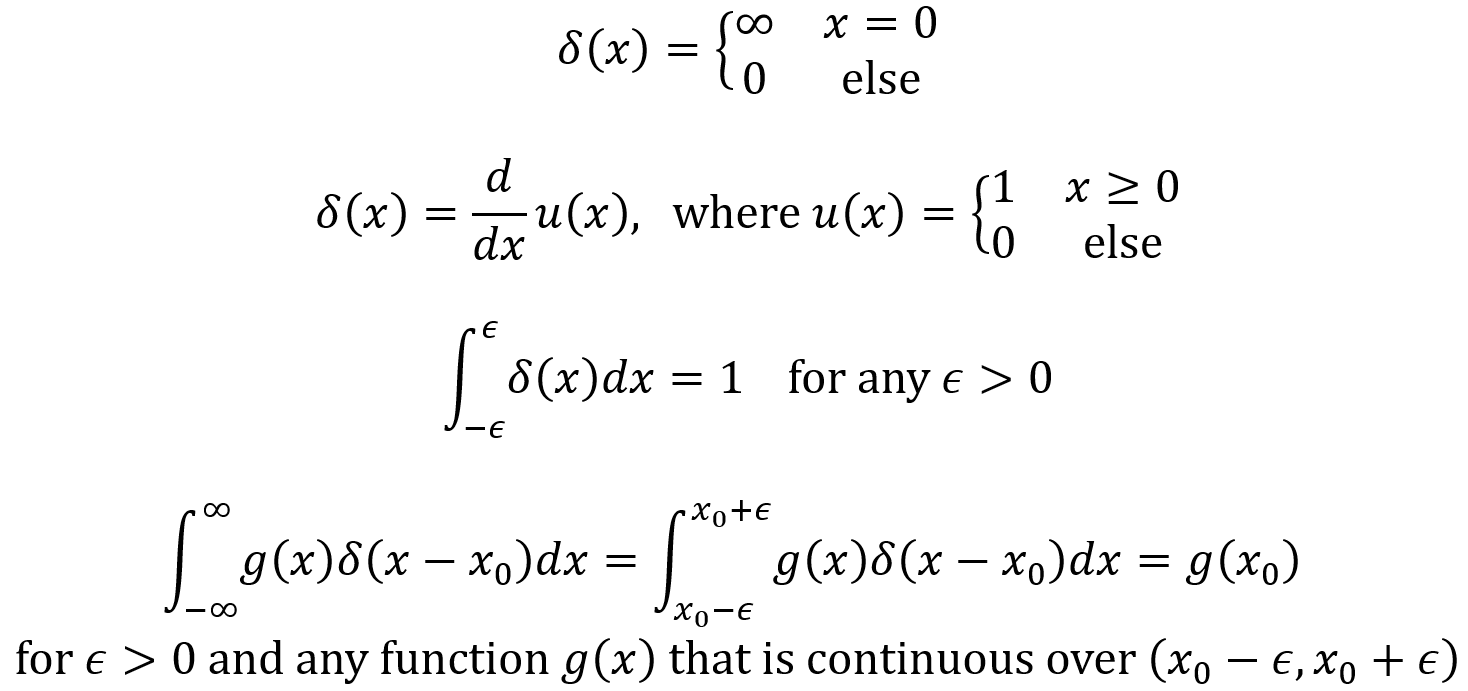
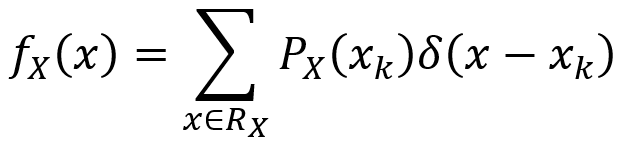
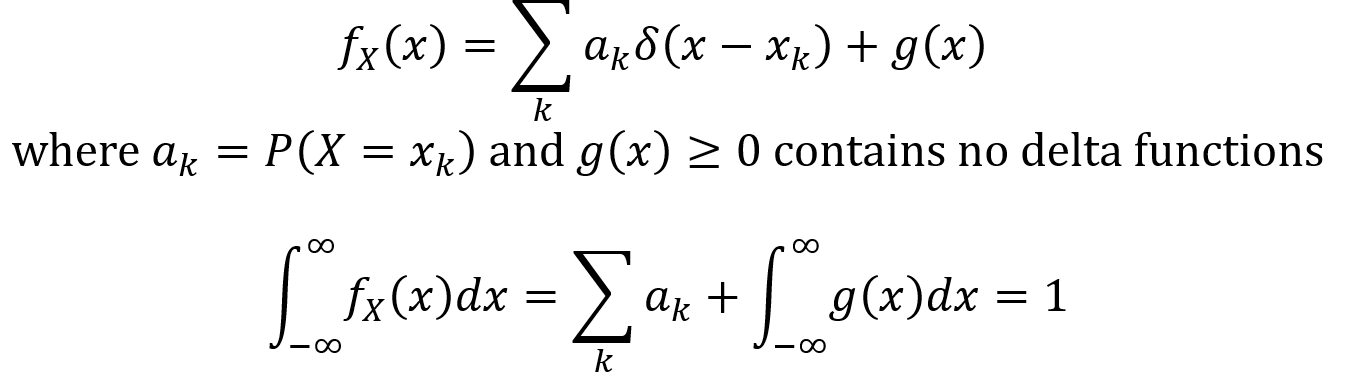



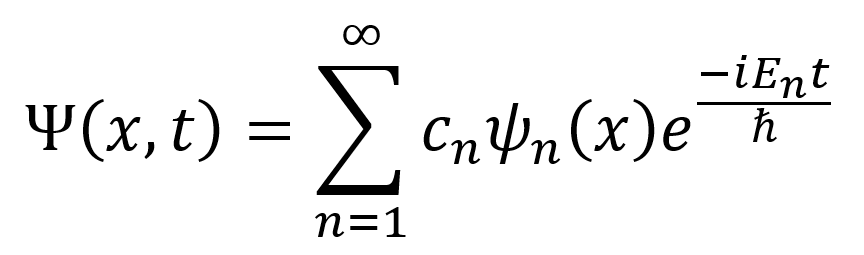
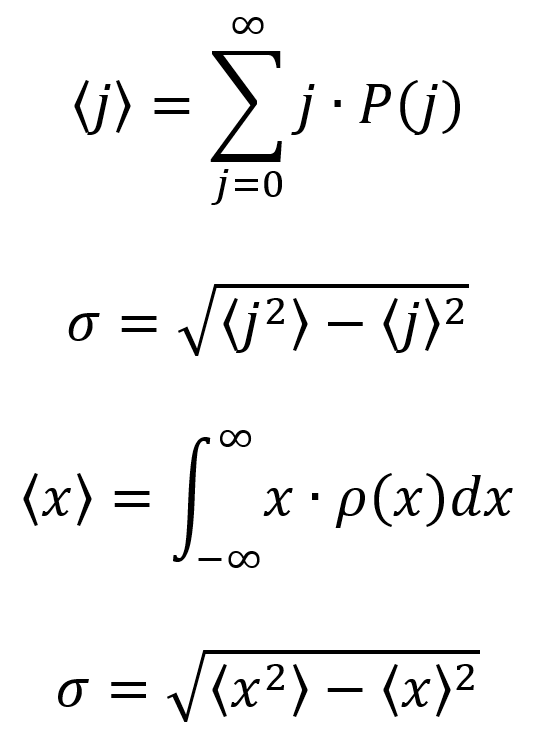
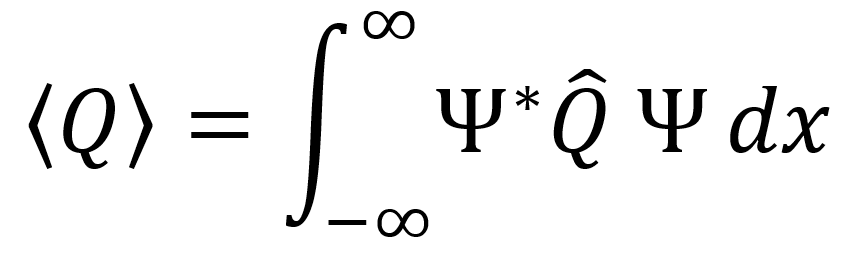

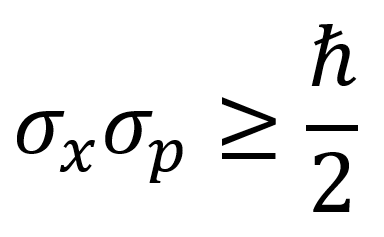
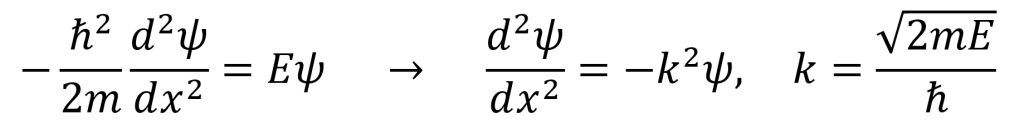
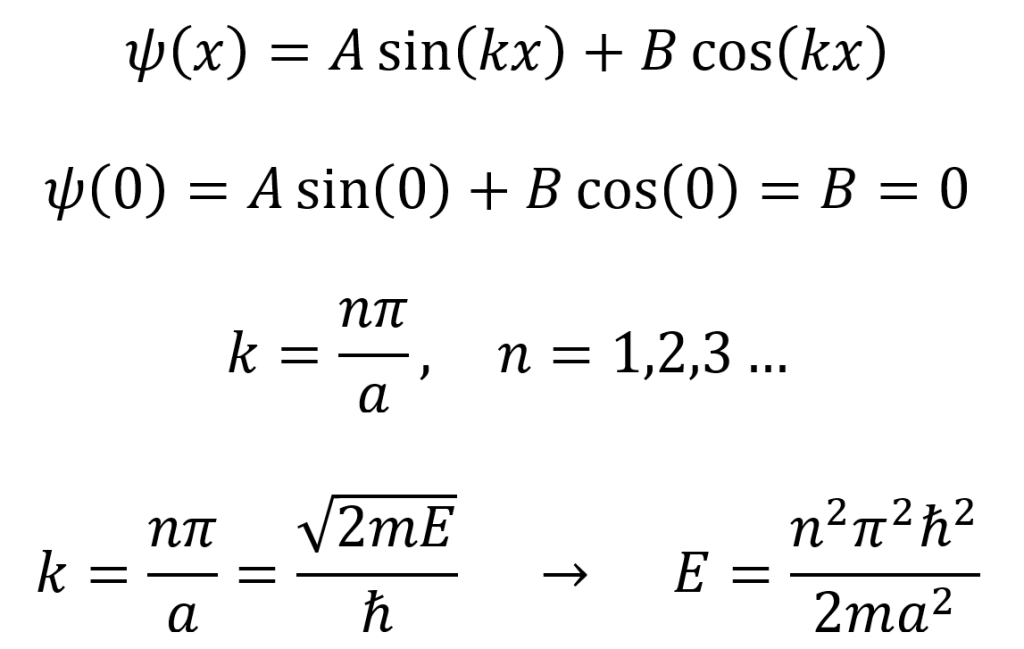
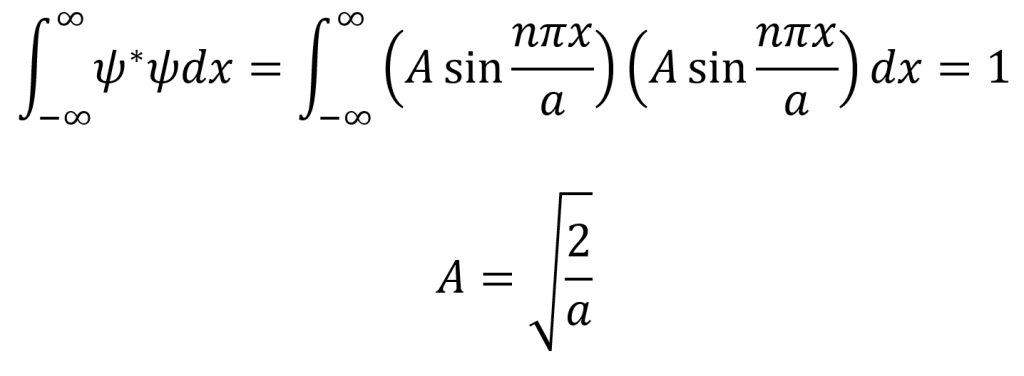


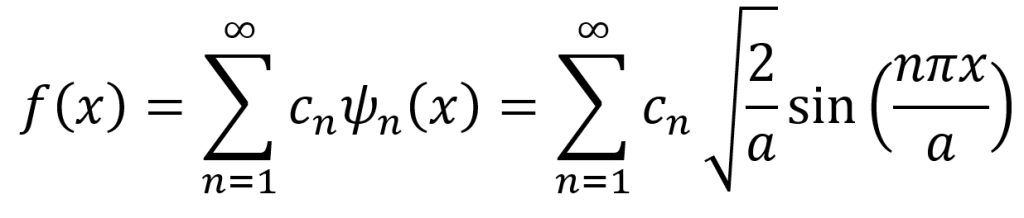
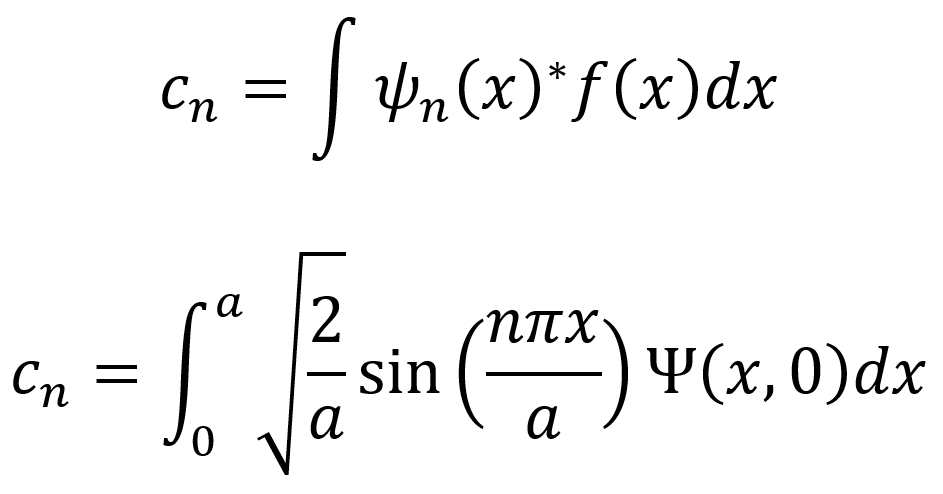



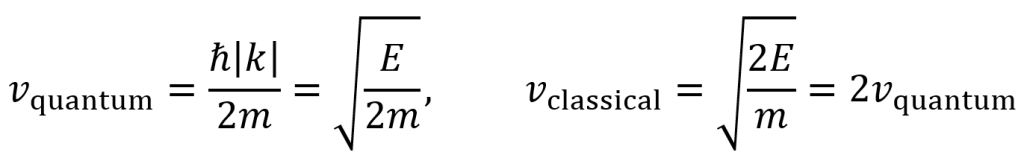


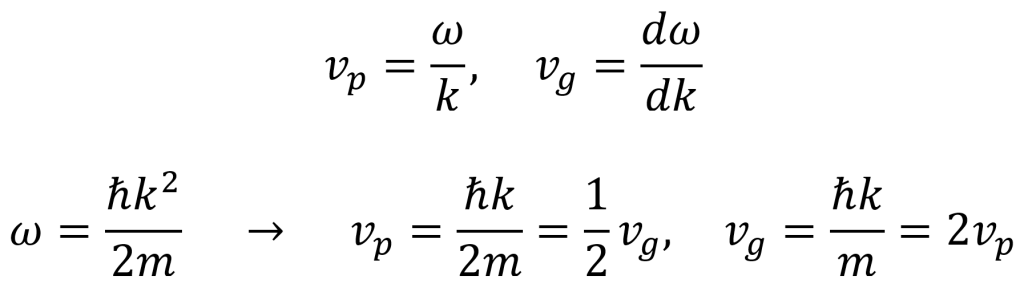

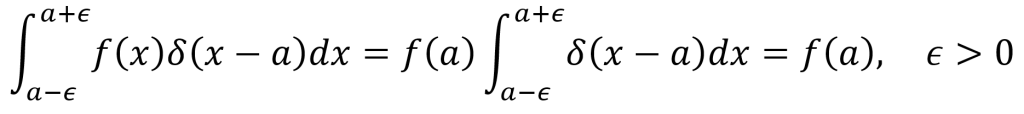
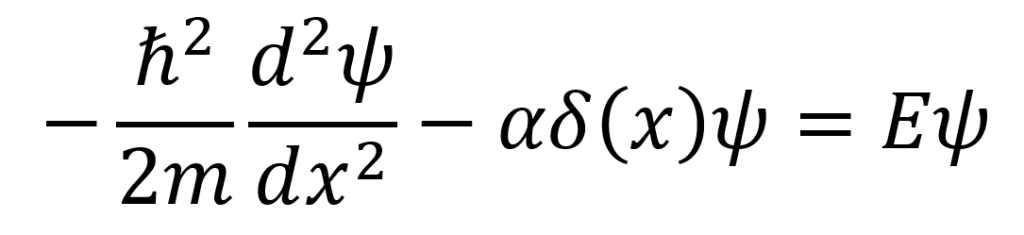
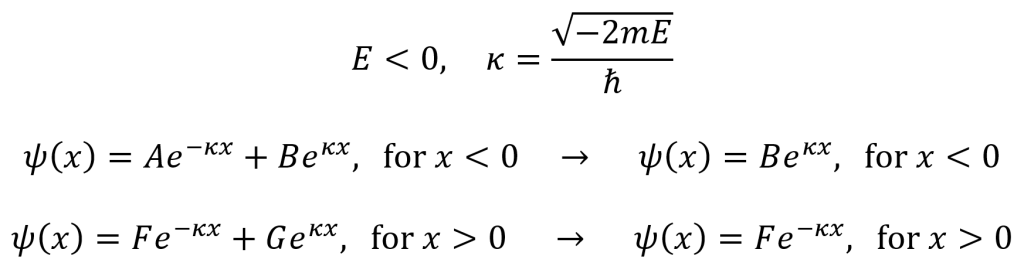



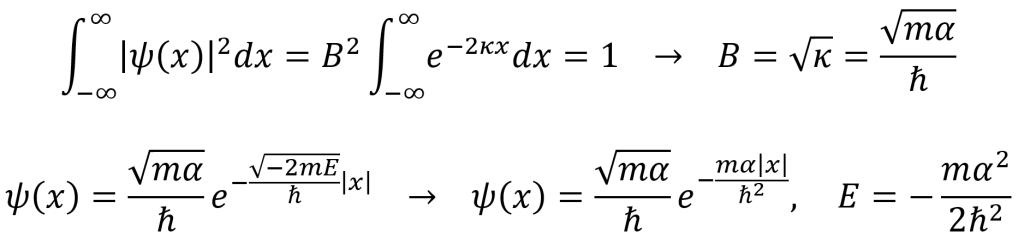



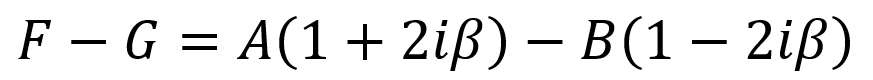
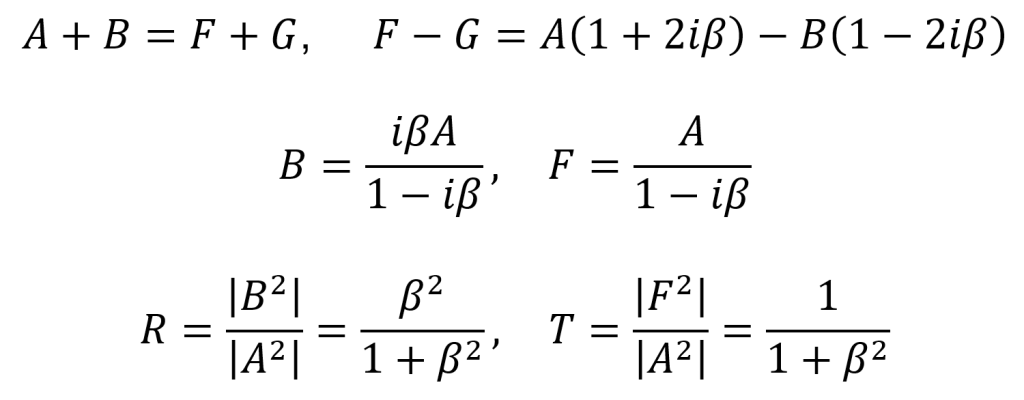
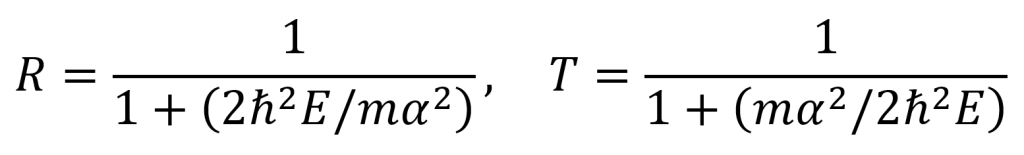





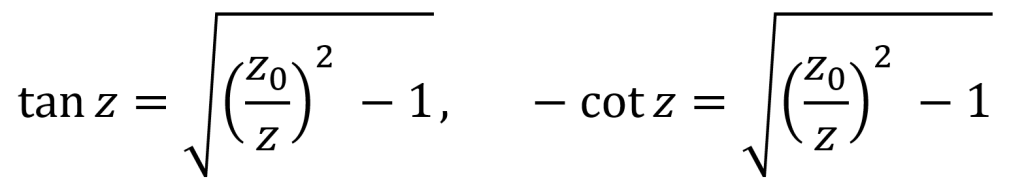
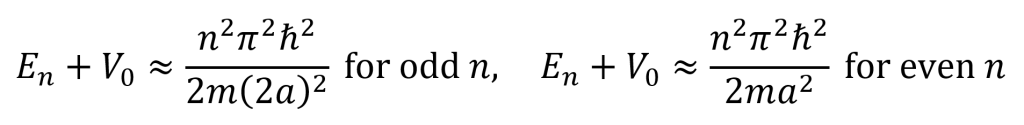
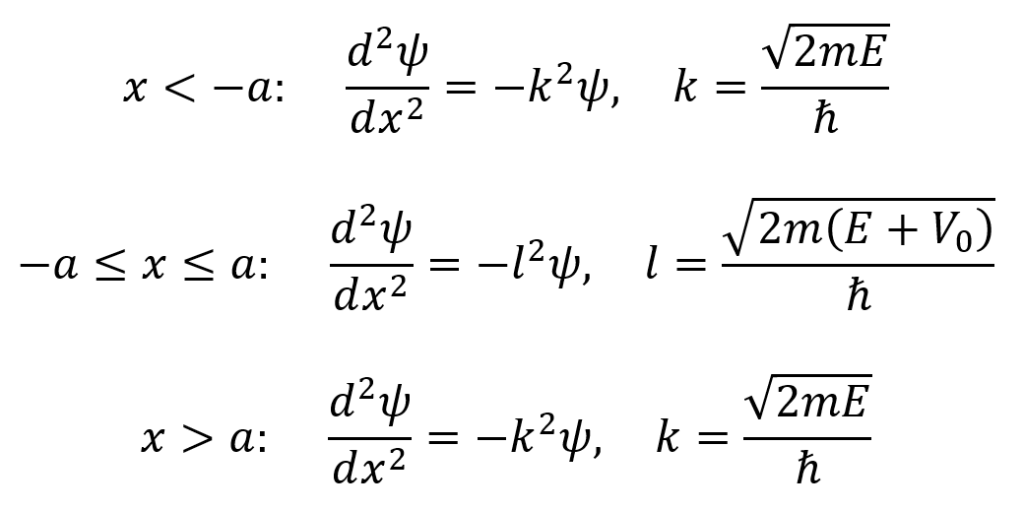


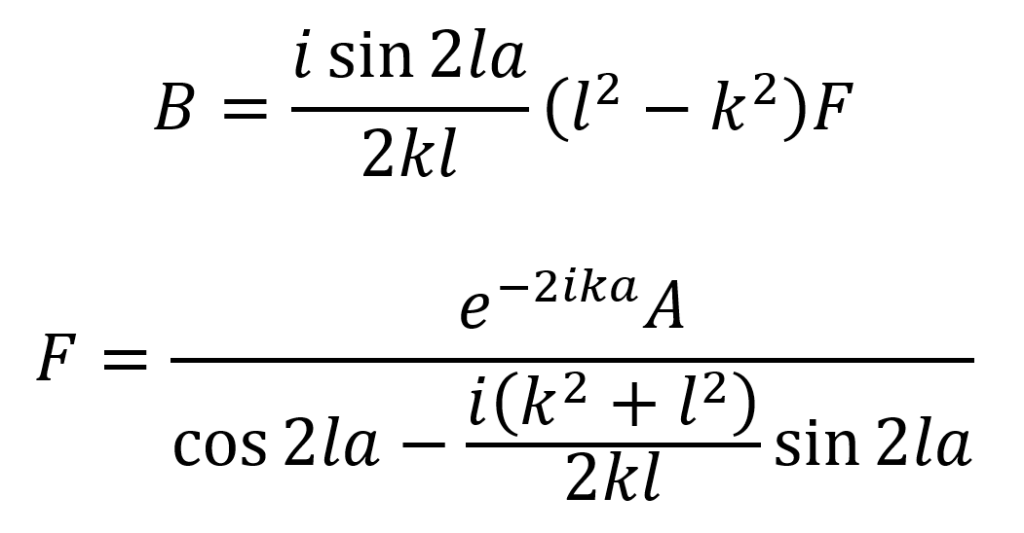

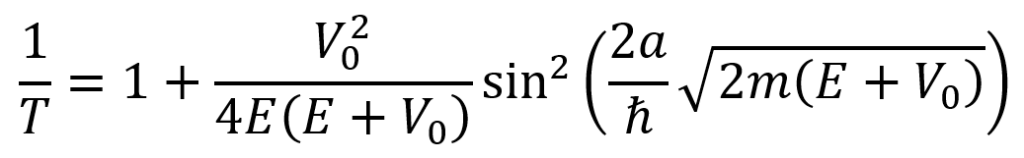





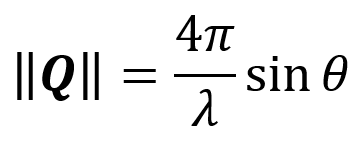
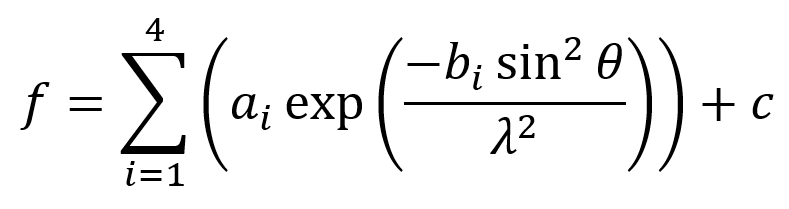

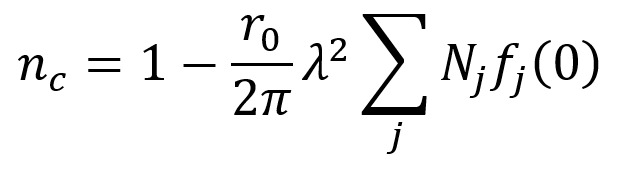

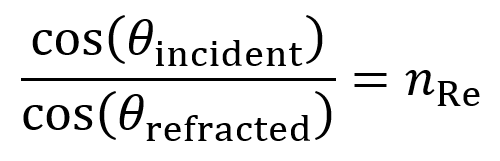
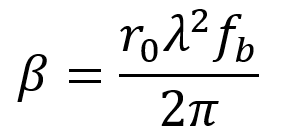









{kind=link}